Explore Simple Game Algorithms with Color Walk: Part 8
We're continuing this ongoing saga of different game algorithms using the simple game Color Walk. In the last post we started exploring the fundamental graph search algorithms with breadth-first search (BFS), because after all, the full set of move choices and resulting board positions of any game can be arranged as a graph. After looking at BFS and finding that we can nominally improve the search for shortest number of moves, on average, it's time we look at the close sibling of BFS: depth-first search (DFS). We'll quickly run into performance issues just like we did for BFS, but let's see if we can come up with a reasonable way to limit DFS so that it can be a useful algorithm.
We saw in the last post that BFS searches a graph (or in the case of games like Color Walk, a tree of board positions generated from moves) one level at a time. All child nodes of the root are searched before any of the children's child nodes are searched, and so forth until the desired search criteria is met. In the case of DFS, the opposite is done. One branch of the tree is searched all the way down to its left-most leaf node, which in the case of game move trees is the end-of-game condition, and then the algorithm backs up and searches down the next branch. The process is repeated until the entire tree is searched, and then the optimal node or path to that node is returned as the result. The following picture illustrates how a tree of height 3 would be searched with DFS:
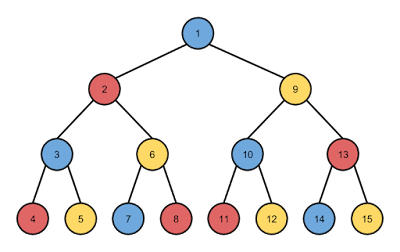
This move tree is drawn for Color Walk assuming there are three colors to pick from, and the numbers in each node show the order that each node is visited during the search. Comparing this to BFS, we'll notice that while BFS has the desirable property that the first node found satisfying the search criteria is also the node with the shortest sequence of moves to reach it, DFS does not have this property. If node 7 is an end-of-game position, but node 13 is also an end-of-game position (assuming nodes 14 and 15 are removed), then after finding node 7, we have to continue searching to be sure we find the best move sequence at node 13.
So why would we want to use DFS if it doesn't find the best node first, like BFS does? First of all, an application may not require the solution with the shortest path, only a solution with a reasonable path, and DFS may be able to find it faster than BFS. This doesn't apply in the case of Color Walk because we are interested in the shortest path, but even in this case we could be satisfied with a path shorter than any others that we've found by other methods.
Secondly, DFS uses less memory than BFS, especially as the tree grows to more and more levels. Searching the above binary tree with a height of 10 using BFS would require a queue with space for 1,024 nodes to hold all of the nodes at the 10th level. On the other hand, DFS keeps track of which path its on using a stack—normally the call stack if it's implemented recursively—and only requires space for 10 nodes to search the same tree. The divergence in memory requirements between the two methods is exponential.
Even though it uses significantly less memory, DFS runs into another problem with Color Walk that can be seen if you think about the extension of the above graph. What happens to that far left path of alternating blue and red moves in the actual game? After not too many moves, we will stop making forward progress in the game because no more blocks will be removed. All of the remaining blocks bordering the grey area would be yellow. We're avoiding choosing the same color multiple times in a row, but that is not enough to avoid searching down a path of infinite length. In fact, the very first path we'll take will be infinite! In addition to that, any path that never chooses one of the colors will go on forever. There are an infinite number of paths in this tree that are infinitely long. Yikes! We could be searching for a long time.
To avoid the problem of infinite paths, we'll have to be careful with implementing DFS for Color Walk. We'll need to either limit the number of moves that we'll search down the tree before giving up on that path, or cut off the search on a given path as soon as we try a move that doesn't remove any blocks, because such a move path can't possibly be optimal. It's likely beneficial to limit the search both ways.
While this problem may seem specific to Color Walk, it is in fact a common problem for DFS to get trapped in loops. Care must be taken to make sure loops are detected and the search of those paths terminated so that the algorithm doesn't run on forever.
With the general theory covered, we are ready to start implementing our DFS algorithm. We'll start with the tactic of limiting the search by the number of moves and terminating search paths when a move is encountered that doesn't remove any blocks. We also need to limit the total search time in some way because otherwise we'll be searching at least as long as the pure BFS algorithm, which was thousands of years. We'll limit the search time to a minute and see what a run on a single board can find. Then we can look at optimizations to search more of the tree in that time before doing a batch run of 100 boards.
The first thing we need to do is add a DFS algorithm to the list of algorithms:
Then the algorithm runs through each control, checking the board for matching blocks. If there are none, it skips to the next control. Otherwise, it calls the recursive function of DFS so that it can search deeper down that path. Each call to dfsNext() passes the state object and returns the state object so that it can be continually passed down to each searched node to be used to limit search depth and get updated as necessary. The current control and number of matches are also passed down to limit searches if the same control is used twice or no new matches are found in the child node.
The algorithm wraps up by copying the move markers from the minimum number of moves found during the search back into the markers array, and then calling doMarkedMoves() to run through those moves on the board. All of this stuff is fairly straightforward, so the real meat of the algorithm remains to be seen in dfsNext():
If there's still time, we'll look at each of the five controls. I implemented this as a for loop instead of a _.each() because I wanted to rotate through the controls, starting with a different control each time, as the search went deeper into the tree. Otherwise, the same controls would always be searched first, giving a long search path and a huge tree to start with that would just waste time because the search wouldn't be making progress towards the end of the game fast enough. Selecting the next control with controls[(i + move} % 5] neatly produces this behavior of rotating through the controls with increasing search depth.
Then we start checking if we should terminate the current search path. If the control is the same as the last control or if this move has already reached the minimum number of moves found so far, we should bail right away. Similarly, if the current control doesn't remove any new blocks, the current path is a dud.
The last check is directly related to the DFS algorithm. If we've reached the end-of-game condition, then we can update the state object with a new minimum moves and the marker array containing the sequence of moves. How do we know for sure that the number of moves is a new minimum? Because if it wasn't, we would have already quit this search path. At this point we quit this search path anyway because we reached the end.
If all of those checks fail, then we drop down to the next level of the tree by calling dfsNext() again with the same parameters, except for incrementing the move number. This algorithm should look very familiar because we've used it extensively already. It has the exact same structure as the Greedy Look Ahead (GLA) algorithm with the only differences being that in GLA we parameterized the search depth so that the user could pick it, and we did a full DFS to that depth so that we could pick the path that maximized some heuristic. Here we're looking for a specific end condition instead of maximizing a metric.
The hope in using the DFS algorithm to its full depth is that the short-path solutions in the move tree are relatively evenly distributed and plentiful, so that even though we can't search the entire tree, we would expect to find a reasonably short solution without searching for too long. How does our algorithm perform in practice? Not too great. On the first board the GLA algorithm finds a solution in 34 moves when looking ahead 6 moves. Letting DFS run for a minute, which is longer than GLA-6 takes to find its solution, turns up a solution in 42 moves. Letting it run for a full 10 minutes doesn't find anything better than that.
As a sanity check for the performance of the algorithm, I decided to put in a counter to track how many nodes were visited during a run. It turns out that over a minute only about 550 nodes were checked, and after 10 minutes about 5,000 nodes were checked. That means it took over 100 milliseconds to check a node, which seems high, even for JavaScript. I put a stop watch in to see how long it was taking to check each node, and I found that when the move depth was shallow, checking a node for removed blocks was quite fast, but as the move depth increased, the time it took to check a node increased rapidly:

We have an average shortest-path of 34.8 moves with a standard deviation of 3.85 moves. This run was decent—not quite as good as the BFS hybrid algorithm, but still pretty good. Here's how it stacks up against a selection of the rest of the algorithms:
We can see that DFS was able to find a minimum move sequence of 25 moves, just like GLA-5, but it didn't perform as well for the mean or maximum. It also had a wider distribution of results than either GLA-5 or BFS. The fact that DFS performs better when the shortest path is shorter and not as well when the shortest path is longer would be due to the DFS taking much longer to search for more optimal paths when the first path it finds is longer and the depth limit for searching the tree is correspondingly deeper. When the algorithm has to search to a depth of 30, it has to search a much larger tree to find a shorter path than if it can start searching to a depth of 15 or so. It may even be able to complete its search of the sub-tree if it finds a very short path early that can limit the depth of the search for the rest of the tree.
A couple ways to improve this hybrid DFS algorithm immediately come to mind. First, we could speed up the search implementation by creating our own stack instead of using JavaScript's call stack. This iterative approach would likely substantially outperform the recursive approach because it shouldn't slow down excessively for deeper search depths. That would allow for searching significantly more nodes in the same amount of time. Second, we could do a preliminary quick search to see how deep the paths are for a few seconds of searching, and then continue using GLA if the path found was too long so as to reduce the search tree height some more before running DFS for the full minute. This strategy would likely bring down the shortest paths for boards that have the longest shortest paths and tighten up the distribution more.
At some point an optimized DFS starts to perform a lot like BFS because it will fully search the section of the tree that it comes to after GLA, and it will end up finding the same shortest-path that BFS would. The advantage of DFS may come from being able to squeeze more performance out of it than BFS, and thus being able to search a larger section of the move tree in the same amount of time. Remember, a DFS algorithm only needs a stack with a size equal to the height of the tree, while BFS will need a queue with a size of at least 4height, making it much less efficient to search large sub-trees.
In either case the improvement of DFS would likely be only marginally better than GLA-5, so we'll move on from BFS and DFS to explore a new shortest-path algorithm next time: Dijkstra's Algorithm.
Article Index
Part 1: Introduction & Setup
Part 2: Tooling & Round-Robin
Part 3: Random & Skipping
Part 4: The Greedy Algorithm
Part 5: Greedy Look Ahead
Part 6: Heuristics & Hybrids
Part 7: Breadth-First Search
Part 8: Depth-First Search
Part 9: Dijkstra's Algorithm
Part 10: Dijkstra's Hybrids
Part 11: Priority Queues
Part 12: Summary
DFS in Theory
We saw in the last post that BFS searches a graph (or in the case of games like Color Walk, a tree of board positions generated from moves) one level at a time. All child nodes of the root are searched before any of the children's child nodes are searched, and so forth until the desired search criteria is met. In the case of DFS, the opposite is done. One branch of the tree is searched all the way down to its left-most leaf node, which in the case of game move trees is the end-of-game condition, and then the algorithm backs up and searches down the next branch. The process is repeated until the entire tree is searched, and then the optimal node or path to that node is returned as the result. The following picture illustrates how a tree of height 3 would be searched with DFS:

This move tree is drawn for Color Walk assuming there are three colors to pick from, and the numbers in each node show the order that each node is visited during the search. Comparing this to BFS, we'll notice that while BFS has the desirable property that the first node found satisfying the search criteria is also the node with the shortest sequence of moves to reach it, DFS does not have this property. If node 7 is an end-of-game position, but node 13 is also an end-of-game position (assuming nodes 14 and 15 are removed), then after finding node 7, we have to continue searching to be sure we find the best move sequence at node 13.
So why would we want to use DFS if it doesn't find the best node first, like BFS does? First of all, an application may not require the solution with the shortest path, only a solution with a reasonable path, and DFS may be able to find it faster than BFS. This doesn't apply in the case of Color Walk because we are interested in the shortest path, but even in this case we could be satisfied with a path shorter than any others that we've found by other methods.
Secondly, DFS uses less memory than BFS, especially as the tree grows to more and more levels. Searching the above binary tree with a height of 10 using BFS would require a queue with space for 1,024 nodes to hold all of the nodes at the 10th level. On the other hand, DFS keeps track of which path its on using a stack—normally the call stack if it's implemented recursively—and only requires space for 10 nodes to search the same tree. The divergence in memory requirements between the two methods is exponential.
Even though it uses significantly less memory, DFS runs into another problem with Color Walk that can be seen if you think about the extension of the above graph. What happens to that far left path of alternating blue and red moves in the actual game? After not too many moves, we will stop making forward progress in the game because no more blocks will be removed. All of the remaining blocks bordering the grey area would be yellow. We're avoiding choosing the same color multiple times in a row, but that is not enough to avoid searching down a path of infinite length. In fact, the very first path we'll take will be infinite! In addition to that, any path that never chooses one of the colors will go on forever. There are an infinite number of paths in this tree that are infinitely long. Yikes! We could be searching for a long time.
To avoid the problem of infinite paths, we'll have to be careful with implementing DFS for Color Walk. We'll need to either limit the number of moves that we'll search down the tree before giving up on that path, or cut off the search on a given path as soon as we try a move that doesn't remove any blocks, because such a move path can't possibly be optimal. It's likely beneficial to limit the search both ways.
While this problem may seem specific to Color Walk, it is in fact a common problem for DFS to get trapped in loops. Care must be taken to make sure loops are detected and the search of those paths terminated so that the algorithm doesn't run on forever.
DFS in Practice
With the general theory covered, we are ready to start implementing our DFS algorithm. We'll start with the tactic of limiting the search by the number of moves and terminating search paths when a move is encountered that doesn't remove any blocks. We also need to limit the total search time in some way because otherwise we'll be searching at least as long as the pure BFS algorithm, which was thousands of years. We'll limit the search time to a minute and see what a run on a single board can find. Then we can look at optimizations to search more of the tree in that time before doing a batch run of 100 boards.
The first thing we need to do is add a DFS algorithm to the list of algorithms:
function Solver() {
// ...
this.init = function() {
// ...
$('#solver_type').change(function () {
switch (this.value) {
// ...
case 'dfs':
that.solverType = that.dfs;
that.metric = areaCount;
break;
default:
that.solverType = that.roundRobin;
break;
}
// ...
});
// ...
} this.dfs = function() {
var state = {min_moves: 50, moves: null, stop_time: performance.now() + 60000};
_.each(controls, function(control) {
var matches = control.checkGameBoard(1, that.metric);
if (matches === 0) return;
state = dfsNext(2, control, matches, state);
});
markers = state.moves;
doMarkedMoves();
}Then the algorithm runs through each control, checking the board for matching blocks. If there are none, it skips to the next control. Otherwise, it calls the recursive function of DFS so that it can search deeper down that path. Each call to dfsNext() passes the state object and returns the state object so that it can be continually passed down to each searched node to be used to limit search depth and get updated as necessary. The current control and number of matches are also passed down to limit searches if the same control is used twice or no new matches are found in the child node.
The algorithm wraps up by copying the move markers from the minimum number of moves found during the search back into the markers array, and then calling doMarkedMoves() to run through those moves on the board. All of this stuff is fairly straightforward, so the real meat of the algorithm remains to be seen in dfsNext():
function dfsNext(move, prev_control, prev_matches, state) {
if (performance.now() > state.stop_time) return state;
for (var i = 0; i < 5; i++) {
var control = controls[(i + move) % 5];
if (control === prev_control || move >= state.min_moves) continue;
var matches = control.checkGameBoard(move, that.metric);
if (matches === prev_matches) continue;
if (endOfGame()) {
state.min_moves = move;
state.moves = markers.slice();
continue;
}
state = dfsNext(move + 1, control, matches, state);
};
return state;
}If there's still time, we'll look at each of the five controls. I implemented this as a for loop instead of a _.each() because I wanted to rotate through the controls, starting with a different control each time, as the search went deeper into the tree. Otherwise, the same controls would always be searched first, giving a long search path and a huge tree to start with that would just waste time because the search wouldn't be making progress towards the end of the game fast enough. Selecting the next control with controls[(i + move} % 5] neatly produces this behavior of rotating through the controls with increasing search depth.
Then we start checking if we should terminate the current search path. If the control is the same as the last control or if this move has already reached the minimum number of moves found so far, we should bail right away. Similarly, if the current control doesn't remove any new blocks, the current path is a dud.
The last check is directly related to the DFS algorithm. If we've reached the end-of-game condition, then we can update the state object with a new minimum moves and the marker array containing the sequence of moves. How do we know for sure that the number of moves is a new minimum? Because if it wasn't, we would have already quit this search path. At this point we quit this search path anyway because we reached the end.
If all of those checks fail, then we drop down to the next level of the tree by calling dfsNext() again with the same parameters, except for incrementing the move number. This algorithm should look very familiar because we've used it extensively already. It has the exact same structure as the Greedy Look Ahead (GLA) algorithm with the only differences being that in GLA we parameterized the search depth so that the user could pick it, and we did a full DFS to that depth so that we could pick the path that maximized some heuristic. Here we're looking for a specific end condition instead of maximizing a metric.
The hope in using the DFS algorithm to its full depth is that the short-path solutions in the move tree are relatively evenly distributed and plentiful, so that even though we can't search the entire tree, we would expect to find a reasonably short solution without searching for too long. How does our algorithm perform in practice? Not too great. On the first board the GLA algorithm finds a solution in 34 moves when looking ahead 6 moves. Letting DFS run for a minute, which is longer than GLA-6 takes to find its solution, turns up a solution in 42 moves. Letting it run for a full 10 minutes doesn't find anything better than that.
DFS in Reality
As a sanity check for the performance of the algorithm, I decided to put in a counter to track how many nodes were visited during a run. It turns out that over a minute only about 550 nodes were checked, and after 10 minutes about 5,000 nodes were checked. That means it took over 100 milliseconds to check a node, which seems high, even for JavaScript. I put a stop watch in to see how long it was taking to check each node, and I found that when the move depth was shallow, checking a node for removed blocks was quite fast, but as the move depth increased, the time it took to check a node increased rapidly:
- Move depth of 20: < 1 msec
- Move depth of 30: 15 msec
- Move depth of 40: 100 msec
- Move depth of 47: 500+ msec
It appears as though function calls take a huge hit in performance as the call stack gets deeper. If I limited the move depth to 30 moves, DFS could search over 6,800 nodes in a minute. That's over an order of magnitude improvement! Of course, it didn't find any solutions, but it could not find a solution much faster.
Two important things that we've learned so far are that (1) short-path solutions are probably not as evenly distributed in the tree as we had hoped, and (2) those solutions are not as plentiful as we would like. We're going to have to set up DFS so that it will have a better chance of success. To get this algorithm to a point where it would actually be usable, we should try combining it with our good-old workhorse, GLA. We can even do the same thing as we did for BFS, and run with GLA for the first 18 moves before switching over to DFS. Then see if we can find a good solution in the next 30 moves so as to keep the call stack short and the searching fast.
This change is super easy to make, as almost everything we need is already available. All we have to do is add a few lines to dfs():
this.dfs = function() {
if (moves < 18) {
this.greedyLookAhead();
return;
}
var state = {min_moves: 30, moves: null, stop_time: performance.now() + 60000};
_.each(controls, function(control) {
var matches = control.checkGameBoard(1, that.metric);
if (matches === 0) return;
state = dfsNext(2, control, matches, state);
});
markers = state.moves;
doMarkedMoves();
}
We have an average shortest-path of 34.8 moves with a standard deviation of 3.85 moves. This run was decent—not quite as good as the BFS hybrid algorithm, but still pretty good. Here's how it stacks up against a selection of the rest of the algorithms:
| Algorithm | Min | Mean | Max | Stdev |
|---|---|---|---|---|
| RR with Skipping | 37 | 46.9 | 59 | 4.1 |
| Random with Skipping | 43 | 53.1 | 64 | 4.5 |
| Greedy | 31 | 39.8 | 48 | 3.5 |
| Greedy Look-Ahead-2 | 28 | 37.0 | 45 | 3.1 |
| Greedy Look-Ahead-5 | 25 | 33.1 | 41 | 2.8 |
| Max Perimeter | 29 | 37.4 | 44 | 3.2 |
| Max Perimeter Look-Ahead-2 | 27 | 35.0 | 44 | 2.8 |
| Perimeter-Area Hybrid | 31 | 39.0 | 49 | 3.8 |
| Deep-Path | 51 | 74.8 | 104 | 9.4 |
| Path-Area Hybrid | 35 | 44.2 | 54 | 3.5 |
| Path-Area Hybrid Look-Ahead-4 | 32 | 38.7 | 45 | 2.7 |
| BFS with Greedy Look-Ahead-5 | 26 | 32.7 | 40 | 2.8 |
| DFS with Greedy Look-Ahead-5 | 25 | 34.8 | 43 | 3.9 |
We can see that DFS was able to find a minimum move sequence of 25 moves, just like GLA-5, but it didn't perform as well for the mean or maximum. It also had a wider distribution of results than either GLA-5 or BFS. The fact that DFS performs better when the shortest path is shorter and not as well when the shortest path is longer would be due to the DFS taking much longer to search for more optimal paths when the first path it finds is longer and the depth limit for searching the tree is correspondingly deeper. When the algorithm has to search to a depth of 30, it has to search a much larger tree to find a shorter path than if it can start searching to a depth of 15 or so. It may even be able to complete its search of the sub-tree if it finds a very short path early that can limit the depth of the search for the rest of the tree.
A couple ways to improve this hybrid DFS algorithm immediately come to mind. First, we could speed up the search implementation by creating our own stack instead of using JavaScript's call stack. This iterative approach would likely substantially outperform the recursive approach because it shouldn't slow down excessively for deeper search depths. That would allow for searching significantly more nodes in the same amount of time. Second, we could do a preliminary quick search to see how deep the paths are for a few seconds of searching, and then continue using GLA if the path found was too long so as to reduce the search tree height some more before running DFS for the full minute. This strategy would likely bring down the shortest paths for boards that have the longest shortest paths and tighten up the distribution more.
At some point an optimized DFS starts to perform a lot like BFS because it will fully search the section of the tree that it comes to after GLA, and it will end up finding the same shortest-path that BFS would. The advantage of DFS may come from being able to squeeze more performance out of it than BFS, and thus being able to search a larger section of the move tree in the same amount of time. Remember, a DFS algorithm only needs a stack with a size equal to the height of the tree, while BFS will need a queue with a size of at least 4height, making it much less efficient to search large sub-trees.
In either case the improvement of DFS would likely be only marginally better than GLA-5, so we'll move on from BFS and DFS to explore a new shortest-path algorithm next time: Dijkstra's Algorithm.
Article Index
Part 1: Introduction & Setup
Part 2: Tooling & Round-Robin
Part 3: Random & Skipping
Part 4: The Greedy Algorithm
Part 5: Greedy Look Ahead
Part 6: Heuristics & Hybrids
Part 7: Breadth-First Search
Part 8: Depth-First Search
Part 9: Dijkstra's Algorithm
Part 10: Dijkstra's Hybrids
Part 11: Priority Queues
Part 12: Summary
0 Response to "Explore Simple Game Algorithms with Color Walk: Part 8"
Post a Comment